In Fig. 1c, at readout 120, a bump can be seen lasting one whole exposure time (30 readouts).
![\begin{figure}
\includegraphics [width=8.8cm,clip]{fig_3nglitch.ps}\end{figure}](/articles/aas/full/1999/14/ds8374/img3.gif) |
Figure 1: These three plots show a single detector response in Analog to Digital Units (ADU) as a function of time, expressed here in number of readouts, where each readout corresponds to 2 s. Three types glitches due to cosmic rays can be found here: a) top: the most common glitches, lasting only one readout. b) middle: a "fader'', occuring around readout 160. This glitch presents a slowly decreasing tail. It has been truncated above 100 ADUs, but its original intensity is 2558 ADUs. c) bottom: a "dipper'', beginning around readout 240. This glitch is followed by a memory effect lasting about 100 readouts. In these observations, the camera draws a mosaic on the sky (raster). Hence as long as an object, such as a star or a galaxy, is in the line of sight of a given pixel, the measured signal increases. A faint galaxy is visible on the bottom plot c) around readout 120, lasting only one position in the raster. Dashed lines mark different observation positions |
The redundancy inside the raster can be used for robust detection. For example, for a raster observation with successive array displacements corresponding to one half of the array on the sky, a source should be detected temporally four times (see Fig. 2).
![\begin{figure}
\begin{tabular}
{cc}
\includegraphics [width=7cm,clip]{fig_hdf_t...
...&
\includegraphics [width=7cm,clip]{fig_hdf_temp4.ps}
\end{tabular}\end{figure}](/articles/aas/full/1999/14/ds8374/img4.gif) |
Figure 2: Four pixel histories (top left pixel (4,12), top right pixel (12,12), bottom left pixel (20,12), and bottom right pixel (27,12)). The signal in ADU is plotted versus the readout number. The dotted lines indicate the change of camera pointing (i.e. between two dotted lines, the observed flux is the same). The same source is seen by the four pixels respectively at position 2,3,4,5. It can be relatively easily detected in pixel (12,12) and (20,12), while it is more difficult to see it in pixels (4,12) and (27,12) |
We tested an automatic "temporal detection technique'' which is described in Appendix A. Although its results are relatively robust, the technique still suffers from severe limitations:
In terms of noise, in the temporal technique the noise standard deviation
is divided by ![]() (where
(where ![]() is the number of readouts
per raster position), while it is divided by
is the number of readouts
per raster position), while it is divided by
![]() (where
(where ![]() is the number of
redundancies inside the raster, i.e. the number of pixels which see
the same sky position) for co-added data.
is the number of
redundancies inside the raster, i.e. the number of pixels which see
the same sky position) for co-added data.
In the Multi-Scale Vision Model (Bijaoui & Rué 1995), an object
in a signal is defined as a set of structures detected in the wavelet
space. The wavelet transform algorithm used for such a decomposition
is the so-called "à trous'' algorithm, which allows us to represent a
signal D(t) by a simple sum of its wavelet coefficients wj and a
smoothed version of the signal ![]() (see Appendix B for more details
about the "à trous'' algorithm)
(see Appendix B for more details
about the "à trous'' algorithm)
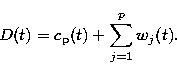 |
(1) |
Once an object is detected in wavelet space, it can be isolated by
searching for the simplest function which presents the same signal in
wavelet space. The problem of reconstruction (Bijaoui & Rué
1995) consists then in searching for a signal V such that its
wavelet coefficients are the same as those of the detected structure. By
noting ![]() , the wavelet transform operator, and
, the wavelet transform operator, and ![]() , the
projection operator in the subspace of the detected coefficients
(i.e.
, the
projection operator in the subspace of the detected coefficients
(i.e. ![]() set all coefficients at scales and positions where
nothing was detected to zero), the solution can be found by minimizing the
following expression:
set all coefficients at scales and positions where
nothing was detected to zero), the solution can be found by minimizing the
following expression:
| (2) |
![\begin{figure}
\includegraphics [width=8.8cm]{8374f3.eps}\end{figure}](/articles/aas/full/1999/14/ds8374/img14.gif) |
Figure 3: The Multiscale Vision Model: contiguous significant wavelet coefficients form a structure, and following an interscale relation, a set of structures form an object. Two structures Sj,Sj+1 at two successive scales belong to the same object if the position pixel of the maximum wavelet coefficient value of Sj is included in Sj+1 |
In ISOCAM data it is the cosmic ray glitches with memory effects which are the typical objects to be extracted from the time sequence of the signal. Indeed, the signal associated with a fader or a dipper type glitch is significant at several frequencies: a strong and rapid peak makes them significant in the highest frequency wavelet coefficient decomposition of the initial signal while the memory effect makes them significant in the lower frequency wavelet coefficients. Hence, the multi-scale approach is an ideal tool to discriminate glitches from real signal. We will call pattern recognition, the action of searching for objects showing properties typical of those expected for faders and dippers.
The idea developed here is to use the multi-scale vision modeling for a decomposition of a signal into its main components. In practice, a simple object reconstruction from the detected structure in the wavelet space, as proposed in Bijaoui & Rué (1995), would produce poor results because of the strong confusion between the numerous objects that can be found in the data. Moreover, wavelet transforms present a drawback: the wings of the wavelet function are negative (so that the integral of the function is zero) which implies that when a positive signal falls onto one wing of the wavelet function it produces a negative signal in the wavelet transform. The quality of the object reconstruction is good only when additional constraints are introduced, such as positivity constraint for positive objects, and negativity constraint for negative objects. An object is defined as positive (or negative) when the wavelet coefficient of the object, which has the maximum absolute value, is positive (or negative).
The problem of confusion between numerous objects can be solved when including a selection criterion in the detection of these objects. Using the knowledge we have about the objects, in this case, glitches, the problem of unknown object reconstruction is reduced to a pattern recognition problem, where the pattern is the glitch itself. We only search for objects which satisfy a given set of conditions in the Multi-Scale Vision Model (MVM). For example, finding glitches of the first type is equivalent to finding objects which are positive, strong, and with a duration shorter than those of the sources. The method that we use for the decomposition of the signal of a given ISOCAM pixel, D(t0... tn), is summarized below:
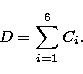 |
(3) |
| (4) |
![\begin{figure}
\includegraphics [width=8.8cm,clip]{fig_iso_plot7.ps}\end{figure}](/articles/aas/full/1999/14/ds8374/img18.gif) |
Figure 4: These two plots show the signal of a single pixel as a function of time before calibration (top, flux in ADU) and after calibration (bottom, flux in ADU/gain/second). The trough following the second glitch (dipper) has disappeared and the remaining signal contains only Gaussian noise (photon noise + readout noise) plus sources (one relatively bright source is located at readout 120, fainter sources will only appear after co-addition of all pixels having seen the same sky position in the final map) |
Figure 4 (bottom) presents the result obtained with this method. The decomposition of the original signal (Fig. 4 top) into its main components is shown in Fig. 5: (a), (b), and (d) are features subtracted from the original signal (short glitches, dipper, and baseline, respectively), which present no direct interest for faint source detection, and only (c) and (e) (bright sources and noise plus faint sources, respectively) are kept for building the final image. The noise must also be kept because faint sources are often detectable only after co-addition of the data.
![\begin{figure}
\includegraphics [width=13cm,clip]{fig_iso_plot6.ps}\end{figure}](/articles/aas/full/1999/14/ds8374/img20.gif) |
Figure 5: Decomposition of the signal into its main components: a) short glitch, b) trough of a dipper, c) bright source, d) baseline, e) noise plus faint sources. The simple sum of the fives components is exactly equal to the original data (see Fig. 2). The calibrated background free data are obtained by addition of signals c) and e). Figure c) shows the reconstruction of a source approximated as a Gaussian, but sources are kept in the signal and their shape differ from one source to the other |
Three kinds of transients must be distinguished:
Figure 6 bottom shows the result after such a treatment. A signal containing a source (top) shows a strong downward transient, which is very clear after deglitching and baseline subtraction (middle). The three successive positions on the array are affected by the transient, which induces ghosts in the final image if they are not removed. The correct shape of the source (bottom) is obtained through the technique developed by Abergel et al. (1996).
![\begin{figure}
\includegraphics [width=8.8cm,clip]{fig_transient.ps}\end{figure}](/articles/aas/full/1999/14/ds8374/img21.gif) |
Figure 6: Examples of transient corrections. Top: signal containing a strong source. Middle: signal after deglitching and subtraction of the baseline. The dashed line shows the configuration limits and crosses indicate the readouts which have been masked. Bottom: signal after the transient correction |
The MMT algorithm is relatively simple. Let med(S,n) be the median
transform of a one-dimensional signal S within a window of dimension
n.
If we define, for ![]() resolution scales, the coefficients:
resolution scales, the coefficients:
 |
(5) | |
| (6) |
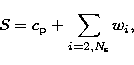 |
(7) |
Applying the multi-scale vision model (MVM) with the MMT, the object reconstruction is straightforward, because no iteration is needed to get a good quality reconstruction.
Figure 7 shows the comparison between the "à trous'' wavelet transform (on the left) and the MMT (on the right) of the input signal in Fig. 1c. In these diagrams, the scale is represented as a function of the time. We can see that with the MMT, it is easier to distinguish sources from glitches. Figure 8 shows the result of MVM using the MMT instead of the "à trous'' algorithm. From (a) to (e), we see the reconstructed source, the dipper, the baseline, the sum of the glitches and the baseline (i.e. non-interesting data), and the original signal from which the signal (d) has been subtracted.
![\begin{figure}
\includegraphics [width=8cm,clip]{fig_wt_glitch1.eps}
\hspace*{1mm}
\includegraphics [width=8cm,clip]{fig_mmt_glitch1.eps}\end{figure}](/articles/aas/full/1999/14/ds8374/img25.gif) |
Figure 7: Comparison between the "à trous'' wavelet transform (left) and the multresolution median transform (right) of the signal of Fig. 1c. Resolution scale is represented versus the time. We note that the separation between the source and the glitch is improved using the MMT |
![\begin{figure}
\includegraphics [width=13cm,clip]{fig_glitch_median.ps}\end{figure}](/articles/aas/full/1999/14/ds8374/img26.gif) |
Figure 8: Decomposition of the signal into its main components using the MMT: a) source, b) dipper, c) baseline, d) Sum of the glitches and the baseline (i.e. non interesting data), and e) original signal minus d) |
Once the calibration is done, the raster map can normally be created, with flat field correction, and all data co-added. The associated rms map can now be used for the detection, which was impossible before due to the strong effect of residual glitches. Since the background has been removed, simple source detection can be done just by comparing the flux in the raster map to the rms map.
Copyright The European Southern Observatory (ESO)