Traditionally, only the two first momenta of H mean m and dispersion
![]() are used. These two parameters are efficient for a Gaussian
distribution. To
characterize some non Gaussian distributions, we have to use more advanced
momenta like the skewness s and/or the curtosis c. We have tested the use of
these parameters in the following. Below, we describe the methodology:
are used. These two parameters are efficient for a Gaussian
distribution. To
characterize some non Gaussian distributions, we have to use more advanced
momenta like the skewness s and/or the curtosis c. We have tested the use of
these parameters in the following. Below, we describe the methodology:
This algorithm is designed to be the fastest one to have a MST on a given
set of points. We normalize the lengths of the MST by using the
Beardwood
et al. (1959)
study. A good approximation of the total length of a MST constructed with a
random set of N points in an area S is ![]() . So,
we divide all the length by this factor (where S is the area of the maximum
rectangle of the point set). We calculate finally the mean m, the dispersion
. So,
we divide all the length by this factor (where S is the area of the maximum
rectangle of the point set). We calculate finally the mean m, the dispersion
![]() , the skewness s and the curtosis c of H.
, the skewness s and the curtosis c of H.
In order to characterize the cuspiness degree of the distributions,
we use three kind of 2D density profiles: points randomly distributed
(Poisson distribution), distributed with a centered King profile (flat
profile in the center) and distributed with a centered NFW profile (cusped
profile in the center: Navarro et al. 1995). We note here that the NFW
expression was for a 3D distribution. Applying it for a 2D set of points
generate a more cusped profile compared to the original 3D NFW. However, we
will speak of "NFW profiles'' hereafter. The way we generated sets of
points with a given profile is described in Adami (1998)
and is related to
the techniques described in Press et al. (1992). If ![]() is the density
and r the radius, we have:
is the density
and r the radius, we have:
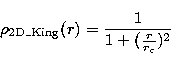
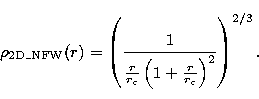
For each set of points with a given profile and a given size, we proceed 100
realizations and so 100 calculations of m, ![]() , s, c. From these data, we
are able to compute the mean value and the dispersion of each parameter m,
, s, c. From these data, we
are able to compute the mean value and the dispersion of each parameter m,
![]() , s or c.
, s or c.
![\begin{figure}
\includegraphics[angle=-90,width=8.8cm,clip]{fig1.ps}\end{figure}](/articles/aas/full/1999/02/ds7993/img10.gif) |
Figure 1:
Variation with the size N of the sample of: up: (m, |
The parameters m and ![]() are asymptotically equal to 0.66
are asymptotically equal to 0.66 ![]() 0.02
and 0.31
0.02
and 0.31 ![]() 0.02 in perfect agreement with Dussert (1988). The error bars
are 3% of the mean value. The final value is reached for a number N of points
in the simulation greater than 125.
0.02 in perfect agreement with Dussert (1988). The error bars
are 3% of the mean value. The final value is reached for a number N of points
in the simulation greater than 125.
The skewness s is well defined for ![]() with a final value of
0.29
with a final value of
0.29 ![]() 0.14. The errors are greater: about 50% of the mean value.
0.14. The errors are greater: about 50% of the mean value.
The curtosis c is well defined only for ![]() with very large error
bars (
with very large error
bars (![]() 100% of the mean value). The final value is 0.33.
100% of the mean value). The final value is 0.33.
![\begin{figure}
\includegraphics[angle=-90,width=17cm,clip]{fig2.ps}\end{figure}](/articles/aas/full/1999/02/ds7993/img15.gif) |
Figure 2:
Variation with the characteristic radius of the King distribution
of: upper left: (m, |
We calculate (m, ![]() , s, c)
for different characteristic radii
, s, c)
for different characteristic radii ![]() of
King and NFW profiles. We use
of
King and NFW profiles. We use ![]() , 75, 100, 125, 150, 175, 200, 225,
250, 275 and 300 kpc. For a given profile and a given characteristic
radius, we simulate 2 sets of points: 250 and 500. We plot the variation
of (m,
, 75, 100, 125, 150, 175, 200, 225,
250, 275 and 300 kpc. For a given profile and a given characteristic
radius, we simulate 2 sets of points: 250 and 500. We plot the variation
of (m, ![]() ) and (s, c) with
) and (s, c) with ![]() for these 2 sets of points in
Fig. 2 for the King profiles. The parameters vary significantly with
for these 2 sets of points in
Fig. 2 for the King profiles. The parameters vary significantly with ![]() at the 3
at the 3 ![]() level. The size of the errors are similar to those for
the Poisson case: very small for (m,
level. The size of the errors are similar to those for
the Poisson case: very small for (m, ![]() ), median for s and very large
for c. The parameters (m,
), median for s and very large
for c. The parameters (m, ![]() ) are not significantly different from the
Poisson case for large characteristic radii (
) are not significantly different from the
Poisson case for large characteristic radii (![]() 225 kpc). The
skewness is significantly different at the 1
225 kpc). The
skewness is significantly different at the 1 ![]() level from the
Poisson case whatever the characteristic radius. The mean value of the
curtosis is also different, but not significantly because of the large error
bars.
level from the
Poisson case whatever the characteristic radius. The mean value of the
curtosis is also different, but not significantly because of the large error
bars.
![\begin{figure}
\includegraphics[angle=-90,width=17cm,clip]{fig3.ps}\end{figure}](/articles/aas/full/1999/02/ds7993/img19.gif) |
Figure 3:
Variation with the characteristic radius of the NFW distribution
of: upper left: (m, |
In Fig. 3 we plot the variations for the NFW profiles and the trends are
very different. All the parameters (m, ![]() , s, c) differ significantly at the
1
, s, c) differ significantly at the
1 ![]() level from the Poisson case. We also notice an important
degeneracy between m and
level from the Poisson case. We also notice an important
degeneracy between m and ![]() .
.
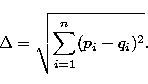
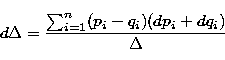
Therefore, we define three distances: ![]() ,
,
![]() , and
, and ![]() .
.
We calculate these distances for the Poisson distribution and the King and the NFW profiles for 3 different sets of points (50, 125 and 500) and for all characteristic radii. We plot (with errors) in Figs. 4, 5 and 6 these distances as a variation of the characteristic radius. We symbolize the null distance as a solid line and we plot the errors on the determination of the parameters of the Poisson distributions.
![\begin{figure}
\includegraphics[angle=-90,width=17cm,clip]{fig4.ps}\end{figure}](/articles/aas/full/1999/02/ds7993/img25.gif) |
Figure 4:
Variation with the characteristic radius of the 3 tested distances
between the Poisson and the King distribution (crosses) and the Poisson
and the NFW distribution (circles). We have 50 points in the samples.
We plot the error bar on each points and we symbolize the error on the
parameters of the Poisson distribution with the two horizontal dashed lines.
The horizontal solid line symbolizes the null distance to the Poisson distribution.
The left part of the figure is for the distance |
![\begin{figure}
\includegraphics[angle=-90,width=17cm,clip]{fig5.ps}\end{figure}](/articles/aas/full/1999/02/ds7993/img26.gif) |
Figure 5:
Variation with the characteristic radius of the 3 tested distances
between the Poisson and the King distribution (crosses) and the Poisson
and the NFW distribution (circles). We have 125 points in the samples.
We plot the error bar on each points and we symbolize the error on the
parameters of the Poisson distribution with the two horizontal dashed lines.
The horizontal solid line symbolizes the nul distance to the Poisson distribution.
The left part of the figure is for the distance |
![\begin{figure}
\includegraphics[angle=-90,width=17cm,clip]{fig6.ps}\end{figure}](/articles/aas/full/1999/02/ds7993/img27.gif) |
Figure 6:
Variation with the characteristic radius of the 3 tested distances
between the Poisson and the King distribution (crosses) and the Poisson
and the NFW distribution (circles). We have 500 points in the samples.
We plot the error bar on each points and we symbolize the error on the
parameters of the Poisson distribution with the two horizontal dashed lines.
The horizontal solid line symbolizes the nul distance to the Poisson distribution.
The left part of the figure is for the distance |
From these figures, we notice the following:
The values of ![]() are higher than those of
are higher than those of ![]() : 400% higher compared to the distance between the point
(m=0,
: 400% higher compared to the distance between the point
(m=0, ![]() ) and the Poisson distribution. The high values and the low
confusions induced by this distance are able to discriminate efficiently the
3 profiles. We see a continuous variation of the distance from the Poisson
distributions to the more cusped ones.
) and the Poisson distribution. The high values and the low
confusions induced by this distance are able to discriminate efficiently the
3 profiles. We see a continuous variation of the distance from the Poisson
distributions to the more cusped ones.
Copyright The European Southern Observatory (ESO)