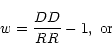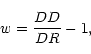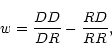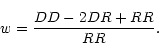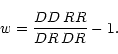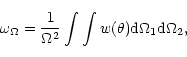The two-point angular correlation function, ![]() ,
is defined as the
joint probability
,
is defined as the
joint probability ![]() of finding sources within the solid angle
elements
of finding sources within the solid angle
elements
![]() and
and
![]() ,
separated by an
angle
,
separated by an
angle ![]() ,
in the form
,
in the form
where N is the mean surface density of galaxies. For a random
distribution of sources
![]() .
Therefore, the angular correlation
function provides a measure of galaxy density excess over that expected for
a random distribution. Various methods for estimating
.
Therefore, the angular correlation
function provides a measure of galaxy density excess over that expected for
a random distribution. Various methods for estimating ![]() have been
introduced, as discussed by Infante (1994). In the present study, a source
is taken as the "centre'' and the number of pairs within annular rings is
counted. To account for the edge effects, Monte Carlo techniques are used by
placing random points within the area of the survey. The most commonly used
estimators in this procedure have the form
have been
introduced, as discussed by Infante (1994). In the present study, a source
is taken as the "centre'' and the number of pairs within annular rings is
counted. To account for the edge effects, Monte Carlo techniques are used by
placing random points within the area of the survey. The most commonly used
estimators in this procedure have the form
where RD is the number of random-data pairs, taking the random
points as centres (Infante 1994). Landy & Szalay (1993, hereafter LS)
introduced the estimator
The uncertainty in w(![]() )
is determined using both Poisson
statistics and 50 bootstrap resamples of the data (Ling et al.
1986). For the latter method, simulated data-sets were generated by
sampling N points with replacement from the true data-set of N points. The
correlation function is then calculated for each of the bootstrap samples,
following the same procedure as that with the original data-set. The
standard deviation around the mean is then used to estimate the
uncertainty in the correlation function.
)
is determined using both Poisson
statistics and 50 bootstrap resamples of the data (Ling et al.
1986). For the latter method, simulated data-sets were generated by
sampling N points with replacement from the true data-set of N points. The
correlation function is then calculated for each of the bootstrap samples,
following the same procedure as that with the original data-set. The
standard deviation around the mean is then used to estimate the
uncertainty in the correlation function.
Although the LS estimator used here is shown to have Poissonian
variance for uncorrelated points (Landy & Szalay 1993), it does not
necessarily behave this way for correlated data. The bootstrap method
is believed to give a more representative estimate of the uncertainty
associated with ![]() .
However, Fisher et al. (1994) carried out
a detailed study of the biases affecting the bootstrap errors
(e.g. cosmic variance, sparse sampling by galaxies of the
underlying density distribution) and concluded that overall the
bootstrap uncertainties overestimate the true errors.
Nevertheless, the bootstrap resampling is a general method for
assessing the accuracy of the angular correlation function estimator and
it will be used here to calculate the formal errors. The uncertainty
associated with
.
However, Fisher et al. (1994) carried out
a detailed study of the biases affecting the bootstrap errors
(e.g. cosmic variance, sparse sampling by galaxies of the
underlying density distribution) and concluded that overall the
bootstrap uncertainties overestimate the true errors.
Nevertheless, the bootstrap resampling is a general method for
assessing the accuracy of the angular correlation function estimator and
it will be used here to calculate the formal errors. The uncertainty
associated with ![]() ,
estimated by the bootstrap resampling
technique, is found to be about three times larger than the Poisson
estimate.
,
estimated by the bootstrap resampling
technique, is found to be about three times larger than the Poisson
estimate.
| Flux density (mJy) | Number of Sources |
| >0.4 | 634 |
| >0.5 | 529 |
| >0.6 | 454 |
| >0.7 | 391 |
| >0.9 | 316 |
| [0.4, 0.9] | 318 |
There is expected be a significant number of physical double sources in a
radio survey with the angular resolution of the Phoenix survey
(
![]() ). In any study of the clustering of radio
galaxies via correlation analysis, these should not be considered as two
sources since both components are formed in the same galaxy. To identify
groups of sources that are likely to be sub-components of a single source
we have employed a percolation technique where all sources within a given
radius are replaced by a single source at an appropriate "centroid'' (Cress
et al. 1996; Magliocchetti et al. 1998). Following the method
developed by Magliocchetti et al. (1998), we vary the link-length in the
percolation procedure according to the flux of each source. In that way,
bright sources are combined, even if their angular separation is large,
whereas faint sources are left as single objects. This technique is based
on the
). In any study of the clustering of radio
galaxies via correlation analysis, these should not be considered as two
sources since both components are formed in the same galaxy. To identify
groups of sources that are likely to be sub-components of a single source
we have employed a percolation technique where all sources within a given
radius are replaced by a single source at an appropriate "centroid'' (Cress
et al. 1996; Magliocchetti et al. 1998). Following the method
developed by Magliocchetti et al. (1998), we vary the link-length in the
percolation procedure according to the flux of each source. In that way,
bright sources are combined, even if their angular separation is large,
whereas faint sources are left as single objects. This technique is based
on the ![]() relation for radio sources, which has been shown to
follow
relation for radio sources, which has been shown to
follow
![]() (Oort 1987a).
(Oort 1987a).
To define the relation between flux density and link-length, the angular separation of double sources versus their total flux is plotted in Fig. 1, out to a separation of 180arcsec. Visual inspection has confirmed that the pairs on the left of Fig. 1 are predominantly sub-components of a single source. This is based on an assessment of the appearance of the object, including the disposition of the sources, the nature of any bridging radiation, and the appearance of source edges. Accordingly, we set the maximum link-length to be
where
![]() is the total flux of each group. This is shown
by the dashed line in Fig. 1 and effectively removes the
majority of visually identified doubles. Moreover, one can apply an
additional criterion to identify genuine doubles, based on the relative
flux densities of the sub-components (Magliocchetti et al. 1998). This is
because lobes of a single radio source are expected to have correlated flux
densities. Here, the groups of sources identified by the percolation
technique are combined only if their fluxes differ by a factor of less than
4. This procedure was repeated until no new groups were found. The final
catalogue consists of 908 objects to the limit of 0.1mJy, with a total of
30 groups of sources being identified and replaced.
is the total flux of each group. This is shown
by the dashed line in Fig. 1 and effectively removes the
majority of visually identified doubles. Moreover, one can apply an
additional criterion to identify genuine doubles, based on the relative
flux densities of the sub-components (Magliocchetti et al. 1998). This is
because lobes of a single radio source are expected to have correlated flux
densities. Here, the groups of sources identified by the percolation
technique are combined only if their fluxes differ by a factor of less than
4. This procedure was repeated until no new groups were found. The final
catalogue consists of 908 objects to the limit of 0.1mJy, with a total of
30 groups of sources being identified and replaced.
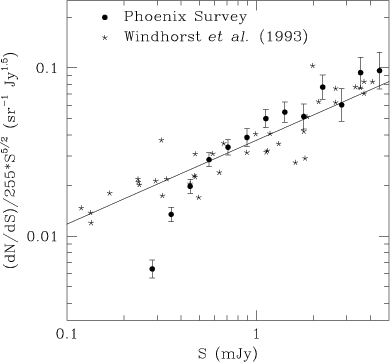
The source counts of the sample, normalised to the Euclidean slope, are
plotted in Fig. 2 along with the radio counts at 1.4GHz
taken from Windhorst et al. (1993). There is a drop in the number
counts below 0.5mJy, as our sample is affected by incompleteness. To
quantify this, we firstly fit a straight line to the source counts of
Windhorst et al. (1993) for flux densities fainter that 5mJy
(continuous line in Fig. 2). We then compare our number
counts at a given flux density bin with those predicted by the fitted
line. We conclude that our sample is
![]() complete to
0.4mJy. This is in agreement with the correction factors for
incompleteness independently derived by Hopkins et al. (1998) accounting
for both resolution effects and the attenuation of the beam away from the
field centre. Therefore, to minimise the effect of incompleteness of the
radio catalogue, when performing the correlation analysis, we restrict
ourselves to a subsample containing all sources brighter than 0.4mJy.
complete to
0.4mJy. This is in agreement with the correction factors for
incompleteness independently derived by Hopkins et al. (1998) accounting
for both resolution effects and the attenuation of the beam away from the
field centre. Therefore, to minimise the effect of incompleteness of the
radio catalogue, when performing the correlation analysis, we restrict
ourselves to a subsample containing all sources brighter than 0.4mJy.
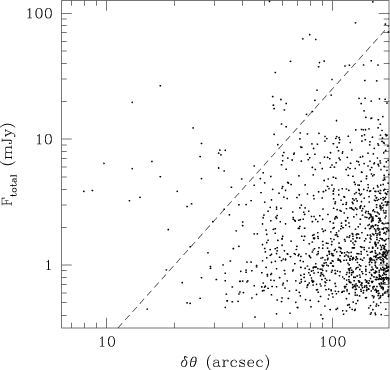 |
Figure 1: Angular separation against total flux density of double sources. The dashed line represents the maximum link-length, for a given flux density, used in the percolation technique |
Finally, before fitting a power law to ![]() ,
we take into account a
bias arising from the finite boundary of the sample. Since the angular
correlation function is calculated within a region of solid angle
,
we take into account a
bias arising from the finite boundary of the sample. Since the angular
correlation function is calculated within a region of solid angle
![]() ,
the background projected density of sources, at a given flux
density limit
,
the background projected density of sources, at a given flux
density limit ![]() ,
is effectively
,
is effectively
![]() (where
(where
![]() is the number of detected objects brighter than
is the number of detected objects brighter than ![]() ).
However, this is an overestimation of the true underlying mean surface
density, because of the positive correlation between galaxies in small
separations, balanced by negative values of
).
However, this is an overestimation of the true underlying mean surface
density, because of the positive correlation between galaxies in small
separations, balanced by negative values of ![]() at larger
separations. This bias, known as the integral constraint, has the effect
of reducing the amplitude of the correlation function by
at larger
separations. This bias, known as the integral constraint, has the effect
of reducing the amplitude of the correlation function by
Copyright The European Southern Observatory (ESO)