Although our set of discovered quasars is relatively small and, thus, cannot by itself provide a definitive answer to the general problem of the spatial distribution of quasars, we consider it useful to independently analyse the present isolated dataset in order to reach a level of knowledge as high as possible on our sample. For the sake of completeness of our subsequent analysis, we define three subsamples that we consider separately: the first one, labelled A1, contains all the 140 primary and secondary candidates; the second one, A2, is related to the 95 primary candidates alone whereas the one labelled A3 deals with the 62 extragalactic objects identified (59 quasars and 3 possible Seyfert 2 galaxies or assimilated). The full analysis is detailed in Gosset (1987a); a complete summary is given here. A first look will be devoted to the 2-D spatial distribution of the objects on the celestial sphere.

Figure 6: Distribution of the quasar candidates of the different
samples in the projected area of the field (A1: 140 primary +
secondary candidates, A2: 95 primary candidates, A3: 62 quasars and related
AGN)
The objects in our samples have been projected on a plane using the equal area projection introduced by Webster (1976b). Figure 6 (click here) presents the projected field. The human eye immediately notices clusters and voids. We will particularly retain the strong association (5 quasars) at the edge of the field in the WSW direction as well as the void in the SSW direction. Whereas a visual inspection may be very powerful in detecting anomalies, only a quantitative approach will help to know whether the observed effects are attributable to the underlying process or are simply due to statistical fluctuations of the sampling. In order to do this, one should make use of a wide variety of statistical methods. Indeed, each method has its own advantages, sensitivity, properties but also has its defects, weaknesses and biases. In addition, some interpretations are quite intricate (see also Gosset et al. 1988). Therefore, an exhaustive knowledge or understanding of the data is not accessible when one uses only one method. The combined results of several independent methods are, without any doubt, essential to reach a high degree of confidence in the conclusions of the analysis. Usually, the null-hypothesis which is tested corresponds to a very simple concept. On the opposite, the complementary to the null-hypothesis, the global alternative hypothesis, is complex, composite. In the case of a rejection of the null-hypothesis, each method will point towards a particular subset of the global alternative hypothesis; the use of several methods and, subsequently, the critical combination of the different subsets will allow a better determination of the true cause of the rejection.
The application of the Extended Kolmogorov-Smirnov (EKS) test introduced in its 2-D version by
Peacock (1983; see also Gosset 1987b) teaches us that subsamples A2
and A3 are in perfect agreement with the null-hypothesis of uniform randomness.
For its part, subsample A1 is tied in with a significance level (SL: probability to observe such a deviation
under the adopted null-hypothesis) of 0.072 which suggests a slight anomaly. We tried to modify the null-
hypothesis by considering non-constant probability density functions (pdf) symmetrical with respect to the
centre of the field (normal distribution; e![]() law following
Peacock 1983, where R is the distance from the plate centre) in order to search for a
better fit while putting in evidence a possible centre-to-edge effect. None of our trials turned out to be
successful, suggesting that one has to deal with a non-localized effect. The position of the largest deviation
between the cumulative distribution function (cdf) and the sample distribution function (sdf) seems to
indicate that the anomaly is associated with the above-mentioned strong association and void.
law following
Peacock 1983, where R is the distance from the plate centre) in order to search for a
better fit while putting in evidence a possible centre-to-edge effect. None of our trials turned out to be
successful, suggesting that one has to deal with a non-localized effect. The position of the largest deviation
between the cumulative distribution function (cdf) and the sample distribution function (sdf) seems to
indicate that the anomaly is associated with the above-mentioned strong association and void.
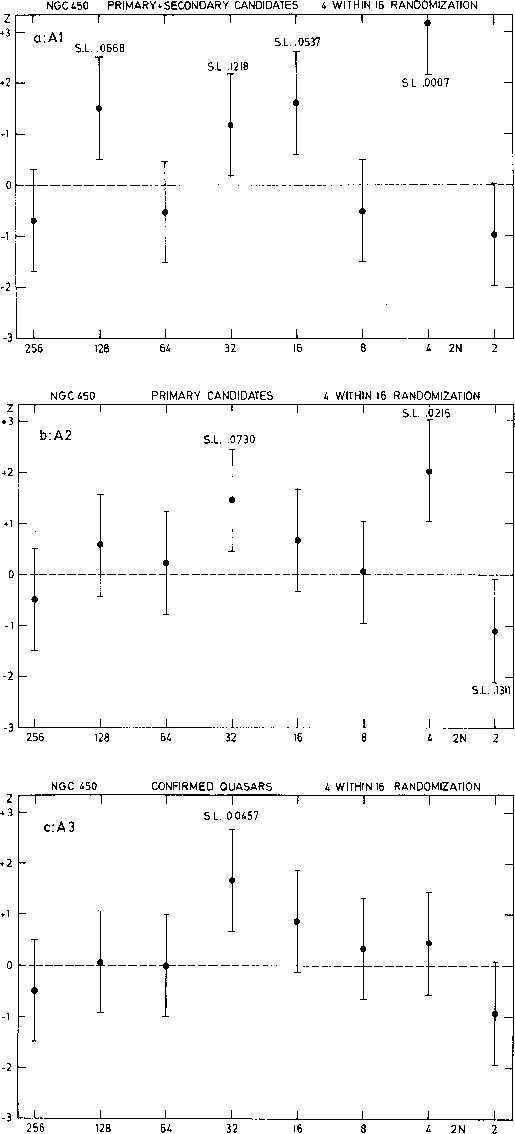
Figure 7: Runs of the Z statistic of the MBA (4 within 16 randomization test) as a function of half the
number of basic bins on one side (![]() ). The explored characteristic scale is given by
4
). The explored characteristic scale is given by
4![]() . The three panels correspond to the three samples A1, A2 and A3. The SL associated with
some deviations of interest is also given
. The three panels correspond to the three samples A1, A2 and A3. The SL associated with
some deviations of interest is also given
The MBA is one of the most ancient methods and a review of the different associated tests of significance is given in Gosset & Louis (1986). The latter also introduced a powerful 2-D test called the 4 within 16 randomization test which analyses the degree of correlation between the counts in adjacent bins. The corresponding normal Z statistic (positive in case of deviation towards clustering, negative in case of regularity) is given in Fig. 7 (click here) as a function of the number of pairs of basic bins. For subsample A1, we note three deviations:
The CFA consists in estimating the underlying pair autocorrelation function versus the angular separation
![]() , by making counts of objects in concentric rings sequentially built-up around each object of the
sample. Such a method is extremely sensitive to edge effects and a correction has to be applied. The only
way to properly perform this correction is to calculate the exact measure of the domain actually explored
when making counts (i.e. to reject the area of the ring situated out of the investigated field). This approach
can however induce systematic effects and the best way to estimate them consists in computing the mean
cross-correlation function between simulated populations of uniformly distributed individuals (representing
the null-hypothesis) and the data (as suggested by
Sharp 1979). One of the estimators, the one corresponding to the true objects taken as
centres and the counts performed on the simulated individuals (labelled w
, by making counts of objects in concentric rings sequentially built-up around each object of the
sample. Such a method is extremely sensitive to edge effects and a correction has to be applied. The only
way to properly perform this correction is to calculate the exact measure of the domain actually explored
when making counts (i.e. to reject the area of the ring situated out of the investigated field). This approach
can however induce systematic effects and the best way to estimate them consists in computing the mean
cross-correlation function between simulated populations of uniformly distributed individuals (representing
the null-hypothesis) and the data (as suggested by
Sharp 1979). One of the estimators, the one corresponding to the true objects taken as
centres and the counts performed on the simulated individuals (labelled w![]() ), is
unbiased and its dispersion can be used to estimate the error on the correlation function. The other estimator
(labelled w
), is
unbiased and its dispersion can be used to estimate the error on the correlation function. The other estimator
(labelled w![]() ), corresponding to the reverse operation, contains the artefacts of
the edge corrections. It should directly be compared with the autocorrelation estimator of the data
w
), corresponding to the reverse operation, contains the artefacts of
the edge corrections. It should directly be compared with the autocorrelation estimator of the data
w![]() .
.
The results of the CFA are given in Fig. 8 (click here). One clearly sees that the artefacts of the edge
corrections are rather low. There is an overdensity of objects at small ![]() (
(![]() ) in all the three
sets; this indicates a clustering at a scale of the order of 12 arcmin. The deviations are approximately
8
) in all the three
sets; this indicates a clustering at a scale of the order of 12 arcmin. The deviations are approximately
8![]() (A1), 2.9
(A1), 2.9![]() (A2) and 5
(A2) and 5![]() (A3): this clustering is significant, a result in good
agreement with the conclusions of the MBA. We have also estimated the deviations relatively to the standard
deviations
(A3): this clustering is significant, a result in good
agreement with the conclusions of the MBA. We have also estimated the deviations relatively to the standard
deviations ![]() computed on the basis of the amount of independent pairs. In this context, we
obtain deviations of 2.1
computed on the basis of the amount of independent pairs. In this context, we
obtain deviations of 2.1![]() , 2.5
, 2.5![]() and 3.7
and 3.7![]() , respectively. We
know that, in this case, the dispersion is usually overestimated. The clustering is undoubtedly present in the
A3 subsample. No significant deviation exists at other scales although a slight overdensity is suggested for
separations
, respectively. We
know that, in this case, the dispersion is usually overestimated. The clustering is undoubtedly present in the
A3 subsample. No significant deviation exists at other scales although a slight overdensity is suggested for
separations ![]() [
[![]() ,
, ![]() ].
].
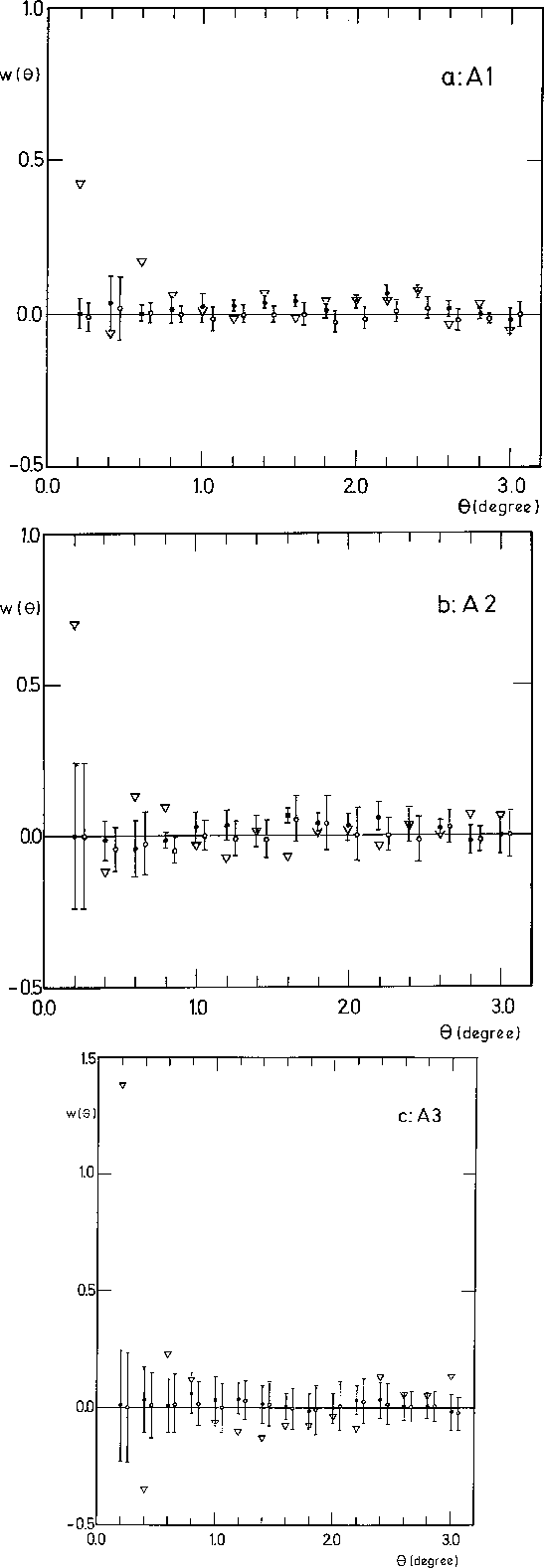
Figure 8: Results of the bi-dimensional CFA. Estimated autocorrelation function as a function of ![]() , the
characteristic angular separation expressed in degrees. The triangles represent the function w
, the
characteristic angular separation expressed in degrees. The triangles represent the function w![]() ; the filled circles represent the function w
; the filled circles represent the function w![]() and the open circles the
function w
and the open circles the
function w![]() . The latter is displaced along the abscissa for the sake of clarity. The
error bars give
. The latter is displaced along the abscissa for the sake of clarity. The
error bars give ![]() 1 standard deviation of the dispersion over the simulations
1 standard deviation of the dispersion over the simulations
The NNA is based on the analysis of the mean distances to ![]() nearest neighbours (see
Clark & Evans 1954; Gosset 1987a;
Rose 1977). It is sensitive to the edge effects but no rigorous CFA-type correction can be
easily applied. This is partly due to the fact that the NNA statistics also depend on higher order terms of the
correlation function. An approximation can be obtained by using simulated populations mimicking the data,
provided that the simulations do reproduce correctly some of the characteristics of the analysed population.
For want of something better, we compared the mean distances to neighbours within the subsamples with
those within simulated uniform populations. This type of correction could be slightly inappropriate, at least
for the A1 subsample, since the genuine population could be non-uniform at large scales. For all the three
subsamples, the first nearest neighbours (up to the fourth one) are too close comparatively to the null-
hypothesis values. The corresponding SL is never lower than 0.05, so that no firm conclusion can be
drawn from the NNA alone. However, the NNA points out to a deviation towards clustering in good
agreement with the previous analyses. Indeed, the mean distance to the first nearest neighbour is of the order
of
10 to 20 arcmin depending on the sample considered. This suggests that the above-mentioned clustering at
nearest neighbours (see
Clark & Evans 1954; Gosset 1987a;
Rose 1977). It is sensitive to the edge effects but no rigorous CFA-type correction can be
easily applied. This is partly due to the fact that the NNA statistics also depend on higher order terms of the
correlation function. An approximation can be obtained by using simulated populations mimicking the data,
provided that the simulations do reproduce correctly some of the characteristics of the analysed population.
For want of something better, we compared the mean distances to neighbours within the subsamples with
those within simulated uniform populations. This type of correction could be slightly inappropriate, at least
for the A1 subsample, since the genuine population could be non-uniform at large scales. For all the three
subsamples, the first nearest neighbours (up to the fourth one) are too close comparatively to the null-
hypothesis values. The corresponding SL is never lower than 0.05, so that no firm conclusion can be
drawn from the NNA alone. However, the NNA points out to a deviation towards clustering in good
agreement with the previous analyses. Indeed, the mean distance to the first nearest neighbour is of the order
of
10 to 20 arcmin depending on the sample considered. This suggests that the above-mentioned clustering at
![]() 10 arcmin is mainly due to pairs of individuals.
10 arcmin is mainly due to pairs of individuals.
The PSA (Webster 1976a) has a good reputation of flexibility and of great sensitivity,
although
Gosset et al. (1988) illustrate a problem of intricate interpretation. The PSA is based on
Fourier transformation of point processes. In the case of the present data, the ![]() statistic
(Webster 1976a) deviates from randomness only for spatial frequencies smaller than
1/
statistic
(Webster 1976a) deviates from randomness only for spatial frequencies smaller than
1/![]() degree
degree![]() , but for these frequencies strictly all the
, but for these frequencies strictly all the ![]() statistics deviate
towards larger values. This result is valid for all the subsamples. Again, this indicates deviations towards
clustering with a typical scale around 15 arcmin. The global Q statistics we derived are
statistics deviate
towards larger values. This result is valid for all the subsamples. Again, this indicates deviations towards
clustering with a typical scale around 15 arcmin. The global Q statistics we derived are

where 2U is the number of degrees of freedom (Webster 1976a).
The Q statistics and the SL reported above refer to all the scales equal to or larger than the one given.
Therefore, they are not univocally linked to the
10-15 arcmin clustering but are influenced by the situation at larger scales. This could explain why the
SL are so small. However, the MBA detects no other deviation for subsample A3: the clustering at
10-15 arcmin is thus probably the main cause in this case. We can estimate a reasonable upper limit on the
SL linked to this clustering by adopting for all the necessary scales a typical ![]() value of 1.15 as
derived from the deviating
value of 1.15 as
derived from the deviating ![]() value at the largest spatial frequencies. For a value 2U = 716,
these
value at the largest spatial frequencies. For a value 2U = 716,
these ![]() values lead to an SL of 0.003, much more secure and realistic as an upper limit. The
above conclusions are independent of the inclusion or exclusion of the 1-D terms in the computation of the 2-
D PSA statistic.
values lead to an SL of 0.003, much more secure and realistic as an upper limit. The
above conclusions are independent of the inclusion or exclusion of the 1-D terms in the computation of the 2-
D PSA statistic.
Concerning the 2-D clustering analysis, we may conclude that a clustering of quasars is clearly present at a scale of about 10 arcmin. It is possible to detect a few groups that participate to this clustering. Let us mention
We will study here the distribution of the redshifts of the objects of subsample A3. The related histogram is
given in Fig. 9 (click here). The main striking feature is the presence of an outstanding excess of objects with a
redshift between
0.9 and 1.0; this has first been reported by Swings et al. (1983).
Other regions with high density are situated around z = 2.0, z = 1.3 and
z=0.4. These inhomogeneities are most likely due to a selection effect,
although an alternative explanation can be found in Arp et al. (1990). Indeed, the emission
lines are determining on the colours of quasars. The quasar will look bluer, and will be easier to detect in
our survey if a strong line is present in the U band. Good examples are the Ly![]() line (for
z
line (for
z ![]() 1.9), the C IV resonance doublet (z
1.9), the C IV resonance doublet (z ![]() 1.3), the Mg II analog
(z
1.3), the Mg II analog
(z ![]() 0.3) and possibly the C III] intercombination line
(z
0.3) and possibly the C III] intercombination line
(z ![]() 0.9). The opposite effect exists when such a line enters the B band. All this should
determine the general appearance of the histogram except for the peak at
0.9). The opposite effect exists when such a line enters the B band. All this should
determine the general appearance of the histogram except for the peak at
![]() which is most probably too narrow and too well-marked to be fully explained by a
similar effect.
which is most probably too narrow and too well-marked to be fully explained by a
similar effect.
![]()
Figure 9: Histogram of the distribution of redshifts of the quasars and assimilated objects; note the surprising
excess in the bin z ![]() [0.9, 1.0]
[0.9, 1.0]
If we adopt, as a null-hypothesis, the uniformity of the distribution of objects with z < 2.3, a
Kolmogorov-Smirnov test associates an SL of 0.05 to our sample. In order to model the above-mentioned
observational biases, we tried to estimate the ![]() colours of quasars as a function of redshift. Then we
arbitrarily fixed the probability to detect the quasar as being proportional to the
colours of quasars as a function of redshift. Then we
arbitrarily fixed the probability to detect the quasar as being proportional to the ![]() excess. Another
approach is to look at the distribution of quasars selected by the same method in current catalogues.
Qualitatively, both ways lead to similar results. We thus derived a new pdf taking into account these
observational biases. This new adopted pdf clearly exhibits three maxima at z = 0.3, 1.3 and 1.9, but
lacks for evidence of strong effects
attributable
to the C III] line. A Kolmogorov-Smirnov test with this new null-hypothesis leads to its acceptance,
which is no clue of the prime cause
of the effect.
excess. Another
approach is to look at the distribution of quasars selected by the same method in current catalogues.
Qualitatively, both ways lead to similar results. We thus derived a new pdf taking into account these
observational biases. This new adopted pdf clearly exhibits three maxima at z = 0.3, 1.3 and 1.9, but
lacks for evidence of strong effects
attributable
to the C III] line. A Kolmogorov-Smirnov test with this new null-hypothesis leads to its acceptance,
which is no clue of the prime cause
of the effect.
Application of the PSA to this 1-D sample reveals a deviation towards regularity with a typical scale of 0.4 to
0.5 in redshift. This again corresponds to the above-mentioned observed effect. If we now adopt the new
non-constant pdf as the null-hypothesis, we have to make use of the GPSA (Generalized PSA; see
Peacock 1983). The run of the GPSA ![]() statistic as a function of the spatial
frequency 1/
statistic as a function of the spatial
frequency 1/![]() (in the redshift domain) is given in Fig. 10 (click here). Only the first point does exhibit
a marked deviation (SL = 0.015). This suggests that the pdf is not fully adapted, which is no surprise
owing to the arbitrariness of its definition; the situation is however improved compared to the PSA case. The
second and the third points do not significantly deviate when taken individually. But they could indicate a
clustering with a typical scale
(in the redshift domain) is given in Fig. 10 (click here). Only the first point does exhibit
a marked deviation (SL = 0.015). This suggests that the pdf is not fully adapted, which is no surprise
owing to the arbitrariness of its definition; the situation is however improved compared to the PSA case. The
second and the third points do not significantly deviate when taken individually. But they could indicate a
clustering with a typical scale ![]() 0.11, an effect to be related to the peak at z
0.11, an effect to be related to the peak at z ![]() [0.9,
1.0].
Nevertheless, the deviation is not significant, corresponding to a global Q = 1.18 with 42 degrees of
freedom. Contrary to what was done in
Swings et al. (1983), the present test is basically continuous and has been applied to a well-
defined sample. Also, we should not forget that one quasar present in the peak has an uncertain redshift and
that only three of them have redshifts confirmed by other authors.
In any case, this anomaly deserves further consideration. Full completion of our different surveys may bring
some clues to the origin of the phenomenon.
[0.9,
1.0].
Nevertheless, the deviation is not significant, corresponding to a global Q = 1.18 with 42 degrees of
freedom. Contrary to what was done in
Swings et al. (1983), the present test is basically continuous and has been applied to a well-
defined sample. Also, we should not forget that one quasar present in the peak has an uncertain redshift and
that only three of them have redshifts confirmed by other authors.
In any case, this anomaly deserves further consideration. Full completion of our different surveys may bring
some clues to the origin of the phenomenon.
![]()
Figure 10: Run of the ![]() statistic of the 1-D GPSA as a function of the spatial frequency (in the
redshift domain); the adopted pdf is discussed in Sect. 6.2 and the analysed sample is A3
statistic of the 1-D GPSA as a function of the spatial frequency (in the
redshift domain); the adopted pdf is discussed in Sect. 6.2 and the analysed sample is A3
![]()
Figure 11: Result of the three-dimensional
CFA for the A4 dataset. Estimated autocorrelation function as a function
of r, the characteristic separation expressed in ![]() Mpc.
The squares represent the function
Mpc.
The squares represent the function ![]() and the filled circles the function
and the filled circles the function ![]() . The error bars are those of the function
. The error bars are those of the function ![]() and represent
and represent ![]() 1
standard deviation of the dispersion over the simulations. By random, we mean populations obtained by
shuffling the redshift values among the quasars and assimilated objects
1
standard deviation of the dispersion over the simulations. By random, we mean populations obtained by
shuffling the redshift values among the quasars and assimilated objects
The three-dimensional - truly spatial - distribution of our quasars can also be investigated. We need for that
an interpretation for the redshifts that could relate them to distances, through a cosmological model. The lack
of observational evidence towards any of the available models,
suggests to use the simplest one. We therefore adopted a Friedmann-Robertson-Walker (FRW) model
without cosmological constant (![]() = 0) and with a deceleration parameter
= 0) and with a deceleration parameter ![]() = 1/2
corresponding to a euclidian geometry (Einstein-de Sitter Universe). The Hubble constant is taken to be
= 1/2
corresponding to a euclidian geometry (Einstein-de Sitter Universe). The Hubble constant is taken to be
![]() Mpc
Mpc![]() . The choice of the model and of the
constants is arbitrary; the results of the clustering analysis are not completely independent of this choice but
they are not too sensitive either.
In the parametric neighbourhood of the chosen FRW model, the impact of the
choice of
. The choice of the model and of the
constants is arbitrary; the results of the clustering analysis are not completely independent of this choice but
they are not too sensitive either.
In the parametric neighbourhood of the chosen FRW model, the impact of the
choice of ![]() becomes just a matter of a scale factor, as is always
the case for
becomes just a matter of a scale factor, as is always
the case for ![]() . The objects have been positioned in such a comoving space; they are all contained in a
0.2
. The objects have been positioned in such a comoving space; they are all contained in a
0.2 ![]() 0.2
0.2 ![]() 2.5
2.5 ![]() Gpc
Gpc![]() parallelepipedic volume. But the one actually
explored is more reminiscent of a truncated pyramid. Practically, the volume is very elongated and the low 3-
D density of objects does not authorize a fine analysis.
parallelepipedic volume. But the one actually
explored is more reminiscent of a truncated pyramid. Practically, the volume is very elongated and the low 3-
D density of objects does not authorize a fine analysis.
We adopted a pdf keeping a constant value within the truncated pyramid and zero outside. Application of the
3-D EKS test
(see Gosset 1987b) leads to the acceptance of the null-hypothesis of uniformity: the
non-uniformities in redshift seem to be diluted here. This is no surprise since
the 1-D EKS test (see Sect. 6.2) was already reporting no strong anomaly;
the addition of two spatial dimensions is expected to wash out the effect.
Application of the GPSA with the same pdf detects no anomaly either, but the analysis is safely restricted to
scales of 65 to ![]() Mpc.
Mpc.
For its part, the application of the MBA (in its version of the 8 within 64 randomization test; see
Gosset & Louis 1986)
is delicate for two related reasons. First, the expectation of the counts in each cell is very low. Second, the
basic bin has, like the full domain, one side 12.5 times greater than the two other ones, implying a mixing of
the scales. A brute application of the test
suggests two deviations towards clustering: the first one, at large scale (1/4 of the side), is marked and
due to the fact that only the truncated pyramid is populated, and not the full parallelepiped; the second one
corresponds to 1/32 of the side which denotes a mixed scale of ![]() Mpc to
Mpc to ![]() Mpc (SL = 0.04). Seyfert 2 galaxies contribute to the latter.
Mpc (SL = 0.04). Seyfert 2 galaxies contribute to the latter.
Application of the CFA is also difficult; the low density does not allow bins smaller than ![]() Mpc. In addition, the elongated shape of the domain renders the volume corrections delicate. In
particular, the CFA is dominated by two objects,
NGC 450#24 and NGC 450#87 which, due to their low redshifts, are rather close to each other and also
close to the small basis of the truncated pyramid. This fact induces large volume corrections and artificially
increases the weight of these two objects in the estimation of the correlation function. Their removal should
not influence our analysis of the quasar distribution and therefore we defined a fourth subsample (A4)
containing 60 objects. The CFA of the A4 dataset leads to the detection of two deviations: the first bin at
Mpc. In addition, the elongated shape of the domain renders the volume corrections delicate. In
particular, the CFA is dominated by two objects,
NGC 450#24 and NGC 450#87 which, due to their low redshifts, are rather close to each other and also
close to the small basis of the truncated pyramid. This fact induces large volume corrections and artificially
increases the weight of these two objects in the estimation of the correlation function. Their removal should
not influence our analysis of the quasar distribution and therefore we defined a fourth subsample (A4)
containing 60 objects. The CFA of the A4 dataset leads to the detection of two deviations: the first bin at
![]() Mpc is
overpopulated, as is also the one at
Mpc is
overpopulated, as is also the one at ![]() Mpc. This analysis
could be vitiated by the inhomogeneities in redshift. A way to get rid
of this effect is to generate the simulated populations used in the
computation of
Mpc. This analysis
could be vitiated by the inhomogeneities in redshift. A way to get rid
of this effect is to generate the simulated populations used in the
computation of ![]() and
and ![]() by shuffling the redshifts among the objects instead of taking the
redshift from a random distribution. Such methods were already used
by Osmer (1981) and Anderson et al. (1988). We thus break the
relation
object-redshift keeping necessarily the same redshift distribution.
by shuffling the redshifts among the objects instead of taking the
redshift from a random distribution. Such methods were already used
by Osmer (1981) and Anderson et al. (1988). We thus break the
relation
object-redshift keeping necessarily the same redshift distribution.
The result of this CFA for the A4 subsample is given in Fig. 11 (click here). The two deviations at
![]() Mpc and at
Mpc and at ![]() Mpc are significant. Due to the low density of the
sample, these deviations can be due to a small number of objects. The first bin deviates because of the
presence of the true pair of quasars
Q0107-025A and Q0107-025B (which, in addition, is situated close to one of
the field edges). The other deviation could be due to two groups of quasars separated by about this distance
of
Mpc are significant. Due to the low density of the
sample, these deviations can be due to a small number of objects. The first bin deviates because of the
presence of the true pair of quasars
Q0107-025A and Q0107-025B (which, in addition, is situated close to one of
the field edges). The other deviation could be due to two groups of quasars separated by about this distance
of ![]() Mpc such as the above-mentioned pair and the pair Q0110-006 and Q0111-007.
Different estimations of the SL related to the deviation of the first bin lead to an upper limit
SL < 0.04. Our 3-D analysis therefore detects a clustering
at an SL of 0.04 and with a typical scale of the order of
Mpc such as the above-mentioned pair and the pair Q0110-006 and Q0111-007.
Different estimations of the SL related to the deviation of the first bin lead to an upper limit
SL < 0.04. Our 3-D analysis therefore detects a clustering
at an SL of 0.04 and with a typical scale of the order of ![]() Mpc. Although formally
correct, these results are to be taken cautiously because the corresponding deviation is essentially due to one
pair. This means that the deletion of only one well selected object among the 60 or 62 is sufficient to cancel
the clustering. Although this fact is not satisfactory, it is the mere consequence of the small size of the
analysed sample. Consequently, neither
is the typical scale meaningfully definable, nor are we authorized to assign
the 3-D clustering property to the quasar population itself. It is interesting to notice that this
Mpc. Although formally
correct, these results are to be taken cautiously because the corresponding deviation is essentially due to one
pair. This means that the deletion of only one well selected object among the 60 or 62 is sufficient to cancel
the clustering. Although this fact is not satisfactory, it is the mere consequence of the small size of the
analysed sample. Consequently, neither
is the typical scale meaningfully definable, nor are we authorized to assign
the 3-D clustering property to the quasar population itself. It is interesting to notice that this ![]() Mpc scale is within a small factor compatible
with the projected scale of 10 arcmin reported in the 2-D analysis. However,
the 2-D clustering is not entirely attributable to Q0107-025A and Q0107-025B.
Mpc scale is within a small factor compatible
with the projected scale of 10 arcmin reported in the 2-D analysis. However,
the 2-D clustering is not entirely attributable to Q0107-025A and Q0107-025B.