Using the stellar spectral types and the photometric observations made through the different pass-bands, we can draw spectral energy distributions (SEDs). By fitting the SED to a Kurucz (1991) model, with solar abundances, appropriate to the MK-type of the star, we obtain information concerning the correct spectral classification, the extinction at the different wavelengths and a possible IR-excess. Below we will discuss briefly the fitting procedure, the selection of the photometric data and the estimation of the Kurucz parameters.
In most cases the value ![]() = 3.1 can be used to correct for the extinction due
to the interstellar medium. However, we have encountered objects which, after
correction with
= 3.1 can be used to correct for the extinction due
to the interstellar medium. However, we have encountered objects which, after
correction with ![]() = 3.1, show SEDs with a small near-infrared excess.
Taking into account previous studies of NGC 6611 and the characteristics of
PMS stars, we assume that the existence of an
infrared excess is caused, either by anomalous extinction towards the
star, or, when no extinction law can be fitted easily, by the presence of
circumstellar dust.
= 3.1, show SEDs with a small near-infrared excess.
Taking into account previous studies of NGC 6611 and the characteristics of
PMS stars, we assume that the existence of an
infrared excess is caused, either by anomalous extinction towards the
star, or, when no extinction law can be fitted easily, by the presence of
circumstellar dust.
The observed magnitudes are first corrected assuming a normal interstellar
extinction law. The resulting extinction-free SED is then compared with the
theoretical SED model of Kurucz (1991), appropriate to the MK type of the
star. When an infrared excess remains, an ![]() value of one tenth higher
is applied. If the infrared excess still
exists, the same procedure is repeated until a best fit between the observed
extinction-free SED and the Kurucz model is obtained according to the
value of one tenth higher
is applied. If the infrared excess still
exists, the same procedure is repeated until a best fit between the observed
extinction-free SED and the Kurucz model is obtained according to the
![]() -test. The
-test. The ![]() value of the best fit is then adopted.
The extinction laws used in this procedure are those of
Steenman & Thé (1991).
value of the best fit is then adopted.
The extinction laws used in this procedure are those of
Steenman & Thé (1991).
The ![]() -test is applied to the difference between the
extinction-free SED and the Kurucz model for all pass bands with wavelengths
between the B passband at 0.434
-test is applied to the difference between the
extinction-free SED and the Kurucz model for all pass bands with wavelengths
between the B passband at 0.434 ![]() m and the near-IR K passband at
2.2
m and the near-IR K passband at
2.2 ![]() m. The errors in the observed data (Koulis 1993) are taken into account in the
m. The errors in the observed data (Koulis 1993) are taken into account in the
![]() -test procedure. For a better accuracy, especially around the
Balmer jump, we have integrated over the response curve of each filter
instead of using monochromatic fluxes.
-test procedure. For a better accuracy, especially around the
Balmer jump, we have integrated over the response curve of each filter
instead of using monochromatic fluxes.
From Tables 1-3 we see that in most cases multiple sets
of photometric data are available. In addition, several stars
display the typical HAeBe characteristic of photometric variability. The ones with
a visual variability range significantly more than 0![]() 2 are marked with a
star in Table 7 (click here).
2 are marked with a
star in Table 7 (click here).
Because of the large amount of data that had slowly accumulated and because
the differences in most of the ![]() , Walraven and JHKLM
data sets are only small, we have decided to average the data sets that
appeared to be compatible, preferably with the highest intensity to acquire
data at maximum light.
The agreements of so many data sets indicate that we are working with
reliable photometric observations. The increase of accuracy
in the various photometric colours implies a more accurate determination of
the colour excess, the photometric spectral type, and consequently the
(possibly anomalous) extinction.
, Walraven and JHKLM
data sets are only small, we have decided to average the data sets that
appeared to be compatible, preferably with the highest intensity to acquire
data at maximum light.
The agreements of so many data sets indicate that we are working with
reliable photometric observations. The increase of accuracy
in the various photometric colours implies a more accurate determination of
the colour excess, the photometric spectral type, and consequently the
(possibly anomalous) extinction.
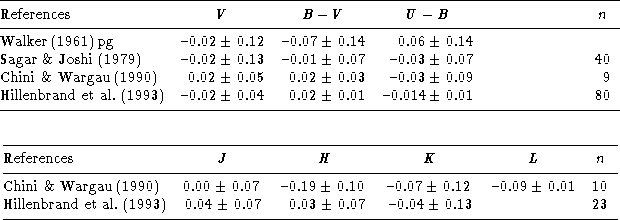
Table 5: Systematic differences of stellar UBV and JHK(L) data
in NGC 6611 for the observations
taken in our programme minus those of other authors. n indicates the number
of available datasets
The photometric data were selected using the following criteria:
For the Walraven data in the visual we have first calculated the corresponding
Johnson visual magnitudes ![]() , using the relation (Pel 1987):
, using the relation (Pel 1987):
![]()
When a ![]() agrees with the V in the
agrees with the V in the ![]() system, it is
considered eligible for further use.
system, it is
considered eligible for further use.
We used a maximum of 5 sets of UBV data per star. For some stars we had
only one set of Johnson ![]() and/or Cousins
and/or Cousins ![]() as noted
in Table 2. Of the available UBVRI data sets we only used the ones
that are in mutual agreement, and for which the relative differences of the
colours are minimal. A similar procedure was applied to the JHK(L)
data sets, but with 3 data sets per star at most.
as noted
in Table 2. Of the available UBVRI data sets we only used the ones
that are in mutual agreement, and for which the relative differences of the
colours are minimal. A similar procedure was applied to the JHK(L)
data sets, but with 3 data sets per star at most.
Before averaging the selected data sets used for the SEDs,
we must note that, when averaging data of different authors, i.e. taken
during different observational periods with different telescopes, different
sets of filters etc., one has to take into account the systematic differences
that may arise between the various observing runs.
Therefore we first must correct the data from all authors with respect to
our data, references 1a-c in Table 2, by adding an average
systematic difference. The systematic differences, as given in
Table 5 (click here), are taken from Thé et al.
(1990) and Hillenbrand
(1993), except for Chini & Wargau's data for
which we calculated the correction ourselves. We also estimated
the average systematic differences for the JHK(L) colours. The
Walraven and ![]() data did not need a correction
as they were made in one system. The same applies to the
data did not need a correction
as they were made in one system. The same applies to the ![]() data of Chini & Wargau (1990).
data of Chini & Wargau (1990).
All corrected and averaged magnitudes and colours are given in Appendix C of Koulis (1993). Table 6 lists the accordingly derived photometric data sets which were used to construct the SED of each star.
To fit the selected photometry to a Kurucz (1991) model,
we first need to consider the best ![]() , E(B-V) and log g
for each object in order to select its appropriate model.
, E(B-V) and log g
for each object in order to select its appropriate model.
In Table 4 there are a number of spectral types that have been derived from the photometric and spectroscopic data of each star which were already in close agreement with each other. As we want one final spectral type for each star we averaged those spectral types, giving a weight of 2 to the averaged spectral type deduced spectroscopically and 1 to the averaged photometric spectral type.
Although the spectral types and therefore the ![]() 's are accurately known,
an SED fit of the Kurucz model to the selected photometry can reveal some small
modifications needed to find the correct Kurucz model.
In these cases we determined a more exact
's are accurately known,
an SED fit of the Kurucz model to the selected photometry can reveal some small
modifications needed to find the correct Kurucz model.
In these cases we determined a more exact ![]() in an iterative way.
in an iterative way.
By this final check of the stellar spectral type we determined the ![]() value from Schmidt-Kaler (1989). The E(B-V) is then the difference
between this
value from Schmidt-Kaler (1989). The E(B-V) is then the difference
between this ![]() value and the (B-V) used in the SED.
value and the (B-V) used in the SED.
Note that a wrong predetermination, á priori or iteratively, of the
spectral type or ![]() , could make a foreground object seem to be a
cluster member and vice versa. In NGC 6611, cluster members should have
, could make a foreground object seem to be a
cluster member and vice versa. In NGC 6611, cluster members should have
![]() .
.
A third but also very important parameter is the star's luminosity class.
Although, varying the spectral type within a luminosity class will not
alter the log g values very much, changing the log g implicitly affects the
![]() and therefore the E(B-V) values of the star.
This parameter can, therefore, affect the cluster membership probability of
a star in two different ways: (1) because it influences its E(B-V), it
could drop below
and therefore the E(B-V) values of the star.
This parameter can, therefore, affect the cluster membership probability of
a star in two different ways: (1) because it influences its E(B-V), it
could drop below ![]() , and (2) the star's position in the HRD.
, and (2) the star's position in the HRD.
Adopting the average of the selected photometric data, listed in Table 6, the
average spectral type, listed in Table 4, and the above mentioned
determination of the E(B-V) value, we are able to fit the SED for each
programme star to a Kurucz model SED. Because of the unknown luminosity class for most
objects we
adopted log g = 4.0 (luminosity class IV or V). The observed magnitudes are first corrected
assuming
a normal extinction law (![]() = 3.1). The extinction-free SED is then
plotted. A comparison is finally made with the theoretical SED model of
Kurucz (1991), appropriate to the MK type of the star.
= 3.1). The extinction-free SED is then
plotted. A comparison is finally made with the theoretical SED model of
Kurucz (1991), appropriate to the MK type of the star.
Although in many cases the SED can be satisfactorily fitted, several cannot. We made the next modifications to
improve the latter
fits:
For some stars, we have to discard certain data sets which are not in mutual
agreement, and reduce the reliability of the SED fitting results:
For W213(1) and W494 the WULBV data;
For W525 we only use the Walraven passbands W and U;
For W617 we discard the Walraven W band and the UBV
reference 1b data;
For W213(2) and W267 we discard the ![]() and
and
![]() data;
data;
For W245 both the ![]() and
and ![]() have to be omitted;
have to be omitted;
For W400 we discard the ![]() and the Walker (1961)
U because it differed too much from other U observations;
and the Walker (1961)
U because it differed too much from other U observations;
For W349 and W402 ![]() have to be ignored;
have to be ignored;
For W455 ![]() is not used;
is not used;
For W300 and W406 we do not use the JHK observations as they
appeared to lie far above or below the best-fit Kurucz
model.
All the resulting plots are presented in Fig. 3 (click here). The final astrophysical parameters as derived and checked by the SED fits are given in Table 7 (click here).
Table 7: Physical data of stars in NGC 6611. Objects indicated by a
star (![]() ) show a visual variability range significantly larger
than 0
) show a visual variability range significantly larger
than 0![]() 2. In the last column the probability of membership is given by the
value P from Thé et al. (1990) and references therein, the values of
Kamp (1974) are given between parentheses. Note that several spectral types
have been adjusted to their SED fits. The luminosities given in Col.
11 are those obtained from
2. In the last column the probability of membership is given by the
value P from Thé et al. (1990) and references therein, the values of
Kamp (1974) are given between parentheses. Note that several spectral types
have been adjusted to their SED fits. The luminosities given in Col.
11 are those obtained from ![]() , whereas those in Col. 12 are obtained
from an integration over the SED (see text)
, whereas those in Col. 12 are obtained
from an integration over the SED (see text)
{kind=link}
{kind=link}