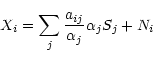Independent component analysis (ICA) is a statistical signal
processing technique that decomposes a set of m observed random
or deterministic data into n independent unobserved source
signals where ![]() and estimates the mixing matrix A. The
simplest model is to consider observed mixed signals X as a
linear combination of unobserved source signals S, based on the
mixing matrix A with added sensor noise N, as shown in
Eq. (1). ICA applications can be BSS, feature
extraction or blind deconvolution. Current solution techniques are
based on a white noise model. From the generalized Anscombe
transform, this hypothesis is satisfied in our experiments.
and estimates the mixing matrix A. The
simplest model is to consider observed mixed signals X as a
linear combination of unobserved source signals S, based on the
mixing matrix A with added sensor noise N, as shown in
Eq. (1). ICA applications can be BSS, feature
extraction or blind deconvolution. Current solution techniques are
based on a white noise model. From the generalized Anscombe
transform, this hypothesis is satisfied in our experiments.
In the BSS context, a full identification of the mixture matrix
A is impossible because the exchange of a fixed scalar factor
between a given source image and the corresponding column of Adoes not affect the observations. For each observed image Xi:
For many decades the KL expansion has been applied for extracting the main information from a set of celestial images (see Murtagh & Heck 1987 for references). From the correlation matrix of the observed signals, the eigenvalues are evaluated in decreasing order, and the most significant ones are kept. From the eigenvectors, orthornormal sources are obtained. The KL expansion allows us to whiten the images and it is considered as the first step of BSS. The resulting demixed images show clearly that non-independence still exists (Fig. 3).
The KL expansion is not the only transformation which leads to a diagonal correlation matrix. Any rotation of the resulting sources keeps this property, but the KL expansion is the one which maximizes the energy concentration.
The optimal rotation results from n(n-1)/2 elementary rotations
of angle
![]() in the plane defined by sources i and
j, n is the number of sources. This decomposition allows one
to design algorithms to optimize an independence criterion.
in the plane defined by sources i and
j, n is the number of sources. This decomposition allows one
to design algorithms to optimize an independence criterion.
Modern ICA work has been inspired by neural networks (Jutten & Hérault 1991). An historical review of this new field can be found in Jutten & Taleb (2000). The ICA concept was defined by Comon (1994). The link between neural network and entropy was proposed by Bell & Sejnowsky (1995), while Amari & Cichocki (1998) introduced an algorithm based on the natural gradient (Amari 1998).
In an environment where no adaptation is needed, one prefers because of computation time and convergence properties to use batch optimization algorithms, which act on the whole set of data without interaction. Second order algorithms are based on the hypothesis of temporally (or spatially) correlated sources and allow efficient second order separation. The cross-correlation between shifted sources taken two by two is decreased, while the source correlation is increased. Other batch computations minimize or maximize contrast functions (Comon 1994) based on higher order cumulants like in JADE (Cardoso & Souloumiac 1993). They allow signals with non-Gaussian PDFs to be separated. Stochastic gradient methods are implemented in neural networks (Hyvärinen & Oja 1997). These methods will be developed below.
Copyright The European Southern Observatory (ESO)